内核初探2
Linux Kernel内核整体架构
这部分内容本身就已经够精简了,这里很大部分内容都是直接从原文章里面摘录下来。
Linux内核的核心功能
如下图所示,Linux内核只是Linux操作系统一部分。对下,它管理系统的所有硬件设备;对上,它通过系统调用,向Library Routine(例如C库)或者其它应用程序提供接口。
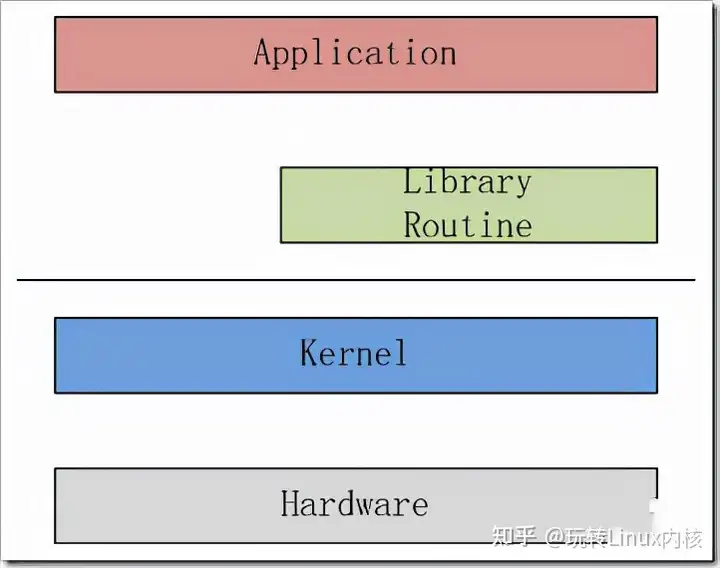
因此,其核心功能就是:管理硬件设备,供应用程序使用。而现代计算机(无论是PC还是嵌入式系统)的标准组成,就是CPU、Memory(内存和外存)、输入输出设备、网络设备和其它的外围设备。所以为了管理这些设备,Linux内核提出了如下的架构。
整体架构和子系统划分
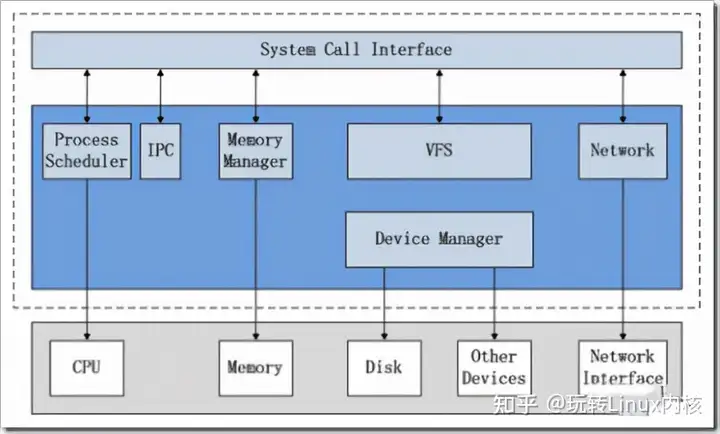
上图说明了Linux内核的整体架构。根据内核的核心功能,Linux内核提出了5个子系统,分别负责如下的功能:
\1. Process Scheduler,也称作进程管理、进程调度。负责管理CPU资源,以便让各个进程可以以尽量公平的方式访问CPU。 \2. Memory Manager,内存管理。负责管理Memory(内存)资源,以便让各个进程可以安全地共享机器的内存资源。另外,内存管理会提供虚拟内存的机制,该机制可以让进程使用多于系统可用Memory的内存,不用的内存会通过文件系统保存在外部非易失存储器中,需要使用的时候,再取回到内存中。 \3. VFS(Virtual File System),虚拟文件系统。Linux内核将不同功能的外部设备,例如Disk设备(硬盘、磁盘、NAND Flash、Nor Flash等)、输入输出设备、显示设备等等,抽象为可以通过统一的文件操作接口(open、close、read、write等)来访问。这就是Linux系统“一切皆是文件”的体现(其实Linux做的并不彻底,因为CPU、内存、网络等还不是文件,如果真的需要一切皆是文件,还得看贝尔实验室正在开发的"Plan 9”的)。 \4. Network,网络子系统。负责管理系统的网络设备,并实现多种多样的网络标准。 \5. IPC(Inter-Process Communication),进程间通信。IPC不管理任何的硬件,它主要负责Linux系统中进程之间的通信。
进程调度(Process Scheduler)
进程调度是Linux内核中最重要的子系统,它主要提供对CPU的访问控制。因为在计算机中,CPU资源是有限的,而众多的应用程序都要使用CPU资源,所以需要“进程调度子系统”对CPU进行调度管理。
进程调度子系统包括4个子模块(见下图),它们的功能如下:
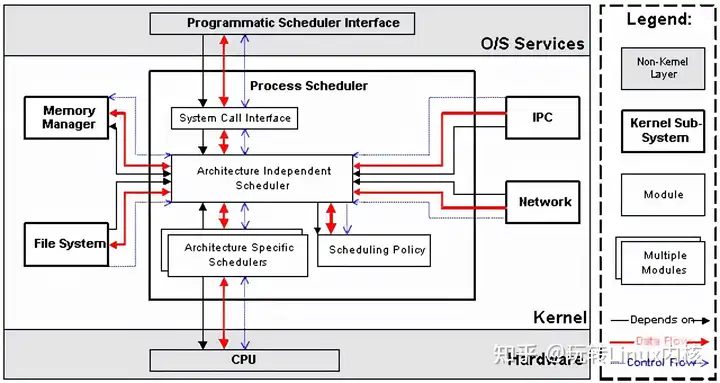
\1. Scheduling Policy,实现进程调度的策略,它决定哪个(或哪几个)进程将拥有CPU。 \2. Architecture-specific Schedulers,体系结构相关的部分,用于将对不同CPU的控制,抽象为统一的接口。这些控制主要在suspend和resume进程时使用,牵涉到CPU的寄存器访问、汇编指令操作等。 \3. Architecture-independent Scheduler,体系结构无关的部分。它会和“Scheduling Policy模块”沟通,决定接下来要执行哪个进程,然后通过“Architecture-specific Schedulers模块”resume指定的进程。 \4. System Call Interface,系统调用接口。进程调度子系统通过系统调用接口,将需要提供给用户空间的接口开放出去,同时屏蔽掉不需要用户空间程序关心的细节。
内存管理(Memory Manager, MM)
内存管理同样是Linux内核中最重要的子系统,它主要提供对内存资源的访问控制。Linux系统会在硬件物理内存和进程所使用的内存(称作虚拟内存)之间建立一种映射关系,这种映射是以进程为单位,因而不同的进程可以使用相同的虚拟内存,而这些相同的虚拟内存,可以映射到不同的物理内存上。
内存管理子系统包括3个子模块(见下图),它们的功能如下:
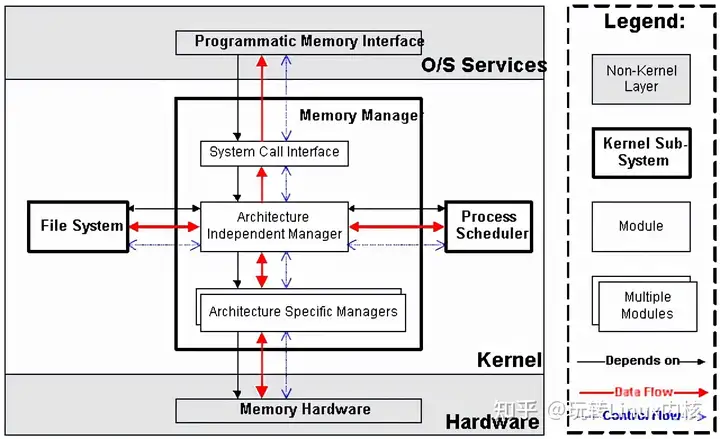
\1. Architecture Specific Managers,体系结构相关部分。提供用于访问硬件Memory的虚拟接口。 \2. Architecture Independent Manager,体系结构无关部分。提供所有的内存管理机制,包括:以进程为单位的memory mapping;虚拟内存的Swapping。 \3. System Call Interface,系统调用接口。通过该接口,向用户空间程序应用程序提供内存的分配、释放,文件的map等功能。
虚拟文件系统(Virtual Filesystem, VFS)
传统意义上的文件系统,是一种存储和组织计算机数据的方法。它用易懂、人性化的方法(文件和目录结构),抽象计算机磁盘、硬盘等设备上冰冷的数据块,从而使对它们的查找和访问变得容易。因而文件系统的实质,就是“存储和组织数据的方法”,文件系统的表现形式,就是“从某个设备中读取数据和向某个设备写入数据”。 随着计算机技术的进步,存储和组织数据的方法也是在不断进步的,从而导致有多种类型的文件系统,例如FAT、FAT32、NTFS、EXT2、EXT3等等。而为了兼容,操作系统或者内核,要以相同的表现形式,同时支持多种类型的文件系统,这就延伸出了虚拟文件系统(VFS)的概念。VFS的功能就是管理各种各样的文件系统,屏蔽它们的差异,以统一的方式,为用户程序提供访问文件的接口。
我们可以从磁盘、硬盘、NAND Flash等设备中读取或写入数据,因而最初的文件系统都是构建在这些设备之上的。这个概念也可以推广到其它的硬件设备,例如内存、显示器(LCD)、键盘、串口等等。我们对硬件设备的访问控制,也可以归纳为读取或者写入数据,因而可以用统一的文件操作接口访问。Linux内核就是这样做的,除了传统的磁盘文件系统之外,它还抽象出了设备文件系统、内存文件系统等等。这些逻辑,都是由VFS子系统实现。
VFS子系统包括6个子模块(见下图),它们的功能如下:
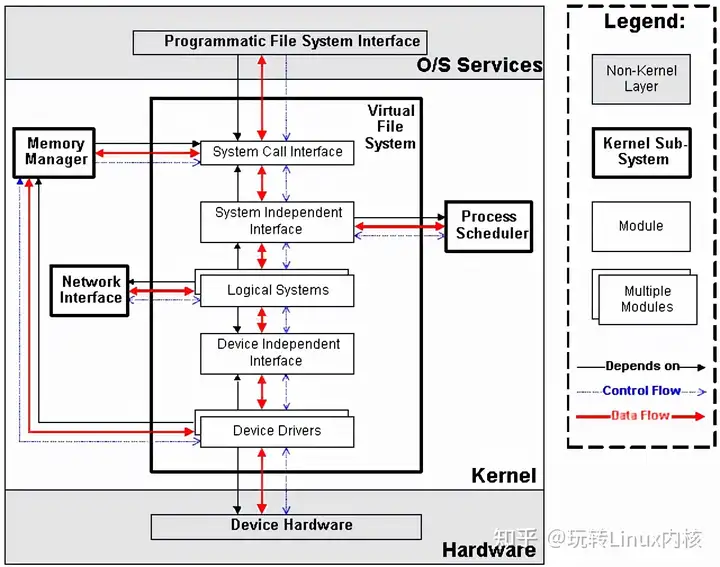
\1. Device Drivers,设备驱动,用于控制所有的外部设备及控制器。由于存在大量不能相互兼容的硬件设备(特别是嵌入式产品),所以也有非常多的设备驱动。因此,Linux内核中将近一半的Source Code都是设备驱动,大多数的Linux底层工程师(特别是国内的企业)都是在编写或者维护设备驱动,而无暇估计其它内容(它们恰恰是Linux内核的精髓所在)。 \2. Device Independent Interface, 该模块定义了描述硬件设备的统一方式(统一设备模型),所有的设备驱动都遵守这个定义,可以降低开发的难度。同时可以用一致的形式向上提供接口。 \3. Logical Systems,每一种文件系统,都会对应一个Logical System(逻辑文件系统),它会实现具体的文件系统逻辑。 \4. System Independent Interface,该模块负责以统一的接口(快设备和字符设备)表示硬件设备和逻辑文件系统,这样上层软件就不再关心具体的硬件形态了。 \5. System Call Interface,系统调用接口,向用户空间提供访问文件系统和硬件设备的统一的接口。
网络子系统(Net)
网络子系统在Linux内核中主要负责管理各种网络设备,并实现各种网络协议栈,最终实现通过网络连接其它系统的功能。在Linux内核中,网络子系统几乎是自成体系,它包括5个子模块(见下图),它们的功能如下:
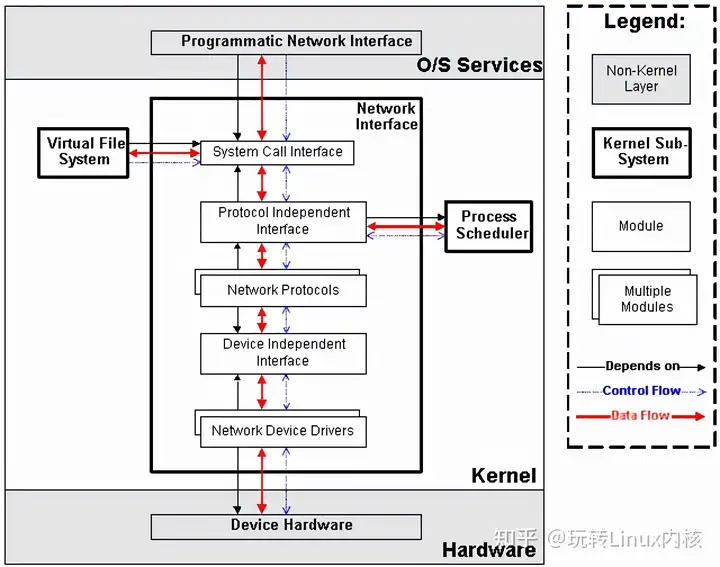
\1. Network Device Drivers,网络设备的驱动,和VFS子系统中的设备驱动是一样的。 \2. Device Independent Interface,和VFS子系统中的是一样的。 \3. Network Protocols,实现各种网络传输协议,例如IP, TCP, UDP等等。 \4. Protocol Independent Interface,屏蔽不同的硬件设备和网络协议,以相同的格式提供接口(socket)。 \5. System Call interface,系统调用接口,向用户空间提供访问网络设备的统一的接口。
IPC
至于IPC子系统,由于功能比较单纯,这里就不再描述了。
Linux内核看socket底层的本质(IO)
一个输入操作通常包括两个阶段:
- 等待数据准备好
- 从内核向进程复制数据
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待数据到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
- Unix 有五种 I/O 模型:
阻塞式 I/O
非阻塞式 I/O
I/O 复用(select 和 poll,epoll)
信号驱动式 I/O(SIGIO)
异步 I/O(AIO)
五大 I/O 模型比较
- 同步 I/O:将数据从内核缓冲区复制到应用进程缓冲区的阶段(第二阶段),应用进程会阻塞。
- 异步 I/O:第二阶段应用进程不会阻塞。
同步 I/O 包括阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O ,它们的主要区别在第一个阶段。
非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞。
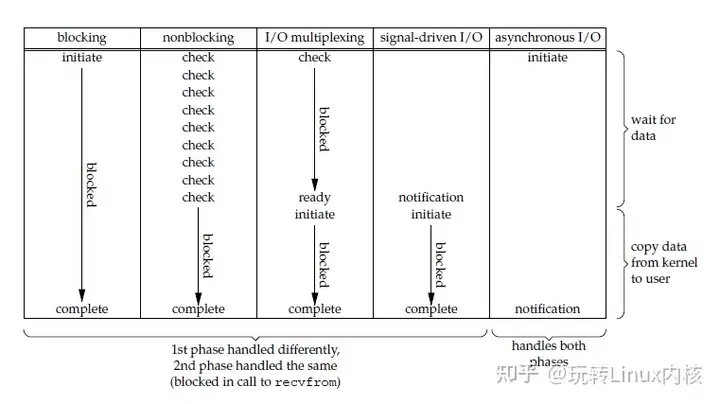
这里通俗的记录我对这五个I/O模型的理解:
- 阻塞式 I/O,recvfrom用于接收 socket 传来的数据,并复制到应用进程的缓冲区 buf 中。调用recvfrom系统调用后进程会一直阻塞,直到内核完成一切操作,所以也称之为阻塞式 I/O。但是这种只是阻塞了当前进程,其他进程仍然正常进行使用,所以CPU利用率还是比较高
- 非阻塞式I/O,这里的应用进程可以继续执行,但是需要不断的执行系统调用来获知 I/O 是否完成,这种方式称为轮询(polling)。由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低。
- I/O复用,这算是最常用的了
- 使用 select 或者 poll 等待数据,并且可以等待多个套接字中的任何一个变为可读。这一过程会被阻塞,当某一个套接字可读时返回,之后再使用 recvfrom 把数据从内核复制到进程中。
- 它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven I/O,即事件驱动 I/O。
- 如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小。
- 信号驱动式I/O,我一开始学感觉这个和I/O复用好像,甚至流程图都很类似。应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中。看到上面的描述可以得知,是通过系统往进程发送一个SIGIO信号后进程再调用recvfrom,所以也称之为信号驱动式I/O
- 异步I/O,应用进程执行 aio_read 系统调用会立即返回,应用进程可以继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。注意是内核完成所有操作后才往进程发送信号
- I/O复用相关概念
文章中介绍了select,poll,epoll等相关内容,但是感觉都不是很详细,所以不做详细记录,等到学到网络协议栈部分再做进一步的学习

Linux用户空间与内核空间通信(Netlink通信机制)
什么是Netlink通信机制
Netlink是linux提供的用于内核和用户态进程之间的通信方式。但是注意虽然Netlink主要用于用户空间和内核空间的通信,但是也能用于用户空间的两个进程通信。只是进程间通信有其他很多方式,一般不用Netlink。除非需要用到Netlink的广播特性时。
那么Netlink有什么优势呢?
一般来说用户空间和内核空间的通信方式有三种:/proc、ioctl、Netlink。而前两种都是单向的,但是Netlink可以实现双工通信。Netlink协议基于BSD socket和AF_NETLINK地址簇(address family),使用32位的端口号寻址(以前称作PID),每个Netlink协议(或称作总线,man手册中则称之为netlink family),通常与一个或一组内核服务/组件相关联,如NETLINK_ROUTE用于获取和设置路由与链路信息、NETLINK_KOBJECT_UEVENT用于内核向用户空间的udev进程发送通知等。
netlink具有以下特点:
- ① 支持全双工、异步通信(当然同步也支持)
- ② 用户空间可使用标准的BSD socket接口(但netlink并没有屏蔽掉协议包的构造与解析过程,推荐使用libnl等第三方库)
- ③ 在内核空间使用专用的内核API接口
- ④ 支持多播(因此支持“总线”式通信,可实现消息订阅)
- ⑤ 在内核端可用于进程上下文与中断上下文
用户态数据结构
首先看一下几个重要的数据结构的关系:
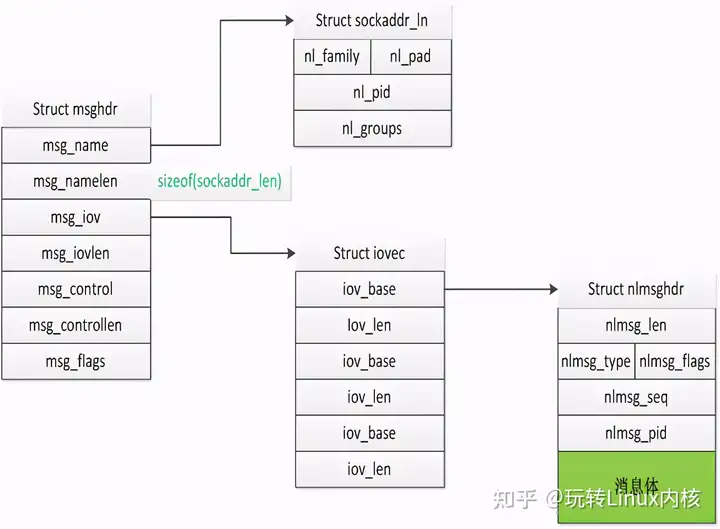
1.struct msghdr
msghdr这个结构在socket变成中就会用到,并不算Netlink专有的,这里不在过多说明。只说明一下如何更好理解这个结构的功能。我们知道socket消息的发送和接收函数一般有这几对:recv/send、readv/writev、recvfrom/sendto。当然还有recvmsg/sendmsg,前面三对函数各有各的特点功能,而recvmsg/sendmsg就是要囊括前面三对的所有功能,当然还有自己特殊的用途。msghdr的前两个成员就是为了满足recvfrom/sendto的功能,中间两个成员msg_iov和msg_iovlen则是为了满足readv/writev的功能,而最后的msg_flags则是为了满足recv/send中flag的功能,剩下的msg_control和msg_controllen则是满足recvmsg/sendmsg特有的功能。
2.struct sockaddr_ln
struct sockaddr_ln为Netlink的地址,和我们通常socket编程中的sockaddr_in作用一样,他们的结构对比如下:
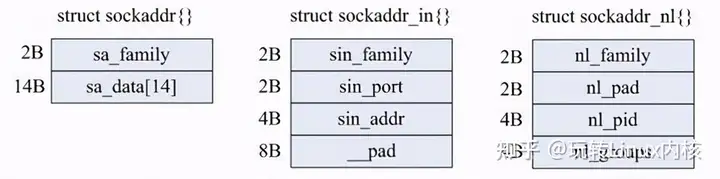
struct sockaddr_nl的详细定义和描述如下:
struct sockaddr_nl
{
sa_family_t nl_family; /*该字段总是为AF_NETLINK */
unsigned short nl_pad; /* 目前未用到,填充为0*/
__u32 nl_pid; /* process pid */
__u32 nl_groups; /* multicast groups mask */
};
(1) nl_pid:在Netlink规范里,PID全称是Port-ID(32bits),其主要作用是用于唯一的标识一个基于netlink的socket通道。通常情况下nl_pid都设置为当前进程的进程号。前面我们也说过,Netlink不仅可以实现用户-内核空间的通信还可使现实用户空间两个进程之间,或内核空间两个进程之间的通信。该属性为0时一般指内核。
(2) nl_groups:如果用户空间的进程希望加入某个多播组,则必须执行bind()系统调用。该字段指明了调用者希望加入的多播组号的掩码(注意不是组号,后面我们会详细讲解这个字段)。如果该字段为0则表示调用者不希望加入任何多播组。对于每个隶属于Netlink协议域的协议,最多可支持32个多播组(因为nl_groups的长度为32比特),每个多播组用一个比特来表示。
3.struct nlmsghdr
Netlink的报文由消息头和消息体构成,struct nlmsghdr即为消息头。消息头定义在文件里,由结构体nlmsghdr表示:
struct nlmsghdr
{
__u32 nlmsg_len; /* Length of message including header */
__u16 nlmsg_type; /* Message content */
__u16 nlmsg_flags; /* Additional flags */
__u32 nlmsg_seq; /* Sequence number */
__u32 nlmsg_pid; /* Sending process PID */
};
消息头中各成员属性的解释及说明:
(1) nlmsg_len:整个消息的长度,按字节计算。包括了Netlink消息头本身。
(2) nlmsg_type:消息的类型,即是数据还是控制消息。目前(内核版本2.6.21)Netlink仅支持四种类型的控制消息,如下:
- a.NLMSG_NOOP-空消息,什么也不做;
- b. NLMSG_ERROR-指明该消息中包含一个错误;
- c. NLMSG_DONE-如果内核通过Netlink队列返回了多个消息,那么队列的最后一条消息的类型为NLMSG_DONE,其余所有消息的nlmsg_flags属性都被设置NLM_F_MULTI位有效。
- d. NLMSG_OVERRUN-暂时没用到。
(3) nlmsg_flags:附加在消息上的额外说明信息,如上面提到的NLM_F_MULTI。
剩下的部分是具体的例子如何编程,这里我就没有进行细看了。